



Antropic lancia Claude Opus 4.5: la battaglia dei giganti dell’Ai si gioca sul codice
Il nuovo modello conquista la vetta dei benchmark con prezzi dimezzati e una sfida che ridefinisce i confini dell’intelligenza artificiale

4' di lettura
4' di lettura
La guerra dell’intelligenza artificiale ha un nuovo campo di battaglia: la programmazione autonoma. E questa settimana ha visto un duello serrato tra due colossi che si contendono il primato tecnologico. Da un lato Anthropic, con il suo Claude Opus 4.5 lanciato lunedì scorso. Dall’altro Google, che pochi giorni prima aveva introdotto Gemini 3, incluso il modello Pro. Una rivalità che non è solo una questione di prestigio, ma che vale miliardi di dollari e ridisegna gli equilibri del settore tech.
Claude primo per il coding
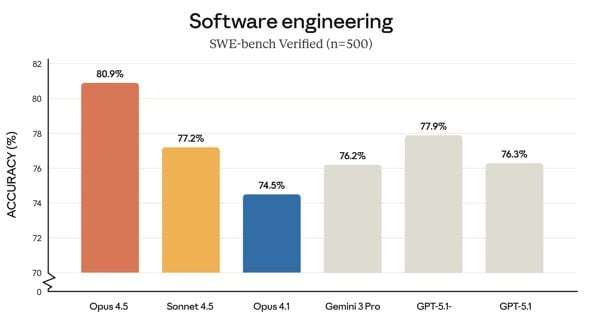
Quando si parla di modelli AI, i benchmark sono il metro di giudizio definitivo. E qui la battaglia si fa interessante. Secondo i dati pubblicati dall’azienda, Claude Opus 4.5 ha conquistato l’80,9% su SWE-bench Verified, uno dei test più citati per valutare le capacità di risolvere problemi reali tratte da repository GitHub. Un risultato che lo pone davanti a tutti: GPT-5.1-Codex-Max di OpenAI si ferma al 77,9%, il precedente Claude Sonnet 4.5 al 77,2%, e Gemini 3 Pro – il rivale diretto – raggiunge il 76,2%.
Loading...
Sono differenze che possono sembrare sottili, ma nel mondo dell’AI ogni punto percentuale conta. Soprattutto quando si tratta di risolvere problemi reali di software engineering. SWE-bench Verified analizza 500 issue autentiche da repository GitHub, problemi che sviluppatori umani hanno realmente affrontato e risolto. La capacità di un modello di capire il contesto, navigare una codebase complessa e produrre una soluzione funzionante è il vero test di intelligenza pratica.
Ma Anthropic non si limit
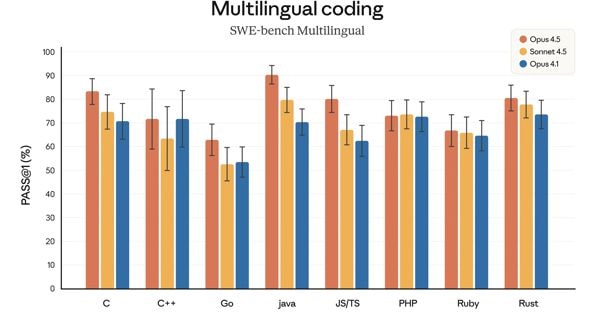
a a reclamare la medaglia d’oro del coding. Su OSWorld, il benchmark che misura l’abilità di utilizzare un computer come farebbe un essere umano, Claude Opus 4.5 raggiunge il 66,3%, confermandosi il miglior modello in assoluto per “computer use” – quella capacità di navigare interfacce, cliccare pulsanti, compilare form come farebbe un umano.

Brand connect
Loading...
